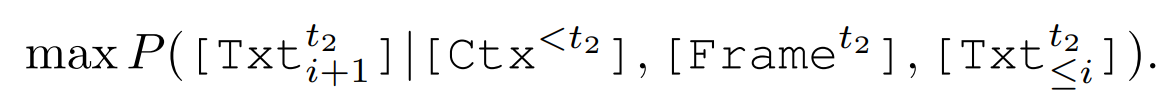이전 논문리뷰에서 다뤘던 Omni-Emotion 후속연구로 진행한 논문입니다. 스트리밍 환경에서 실시간 상호작용개념을 소개하면서 기존 오프라인 비디오에 집중했던 연구보다 더욱 실제 환경에 적합해 보입니다.

1. Introduce
기존 LMM은 오프라인 비디오 기반이기 때문에, 전체 비디오를 한 번에 보고 처리하는 데에 초점이 맞춰져 있기 때문에 공간적, 시간적, 비디오 전반의 종합적인 이해도가 높은 편입니다. 하지만 스트리밍 비디오는 전체 비디오의 맥락을 미리 알 수 없고, 이후 데이터도 계속 들어오기 때문에 지속적인 업데이트가 필요합니다.
스트리밍과 오프라인 비디오 이해의 3가지 차이점은 다음과 같습니다.
- 시간 민감성 (Time-sensitivity)
- 지금 무슨 일이 벌어지는 지는 시간에 따라 다른 답변을 요구할 수 있으며 모델은 적절한 타이밍에 정확한 응답이 필요합니다.
- 옴니 모달리티 (Omni-modality)
- 스트리밍 비디오는 항상 오디오와 함께 들어옵니다.
- 상호작용성 (Interactivity)
- Non-awakening interaction : 사용자는 언제든 에이전트와 상호작용이 가능합니다.
- Interruption : 사용자가 대화를 멈추거나 주제를 바꿀 수 있습니다.
- Proactive output : 에이전트도 판단 가능해야합니다.
본 연구에서는 상호작용 및 시각적 지시를 이해하고 이에 대해 즉각적 피드백을 수행시키기 위해 Visual Instruction Feedback을 이용하였고 이는 사전 정의된 일곱가지의 서브태스크를 지정해놓았습니다.
ViSpeak 모델은 Omni-modal을 기반으로 3단계 파인튜닝을 진행했습니다.
1. Template Alignment
기존 오프라인 모델 --> 스트리밍 템플릿에 맞춤
입력과 응답이 동시에 시간 정렬
중간에 끊는 Interruption 기능
2. Streaming Finetuning
실시간 QA 능력 + Proactive output
3. ViSpeak-Instruct Finetuning
Visual Instruction Feedback 태스크를 위한 tuning
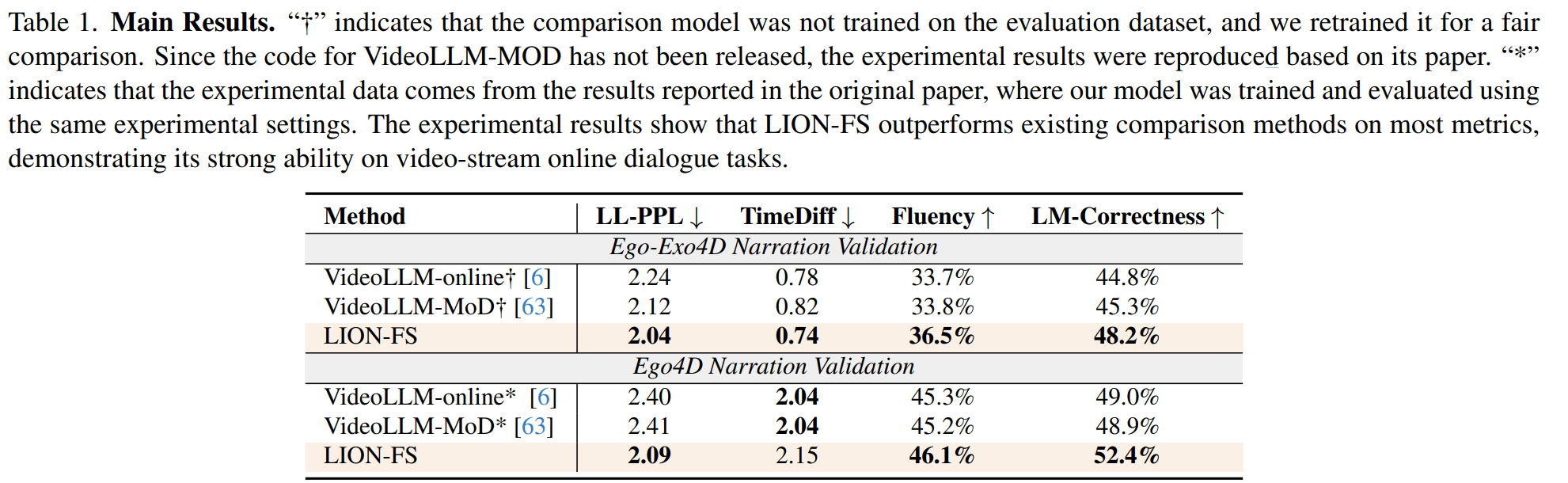
결과적으로 StreamingBench ( 62.00) 및 OVO-Bench (61.08) 에서 SOTA 성능을 달성해 GPT-4o에 필적한 연구입니다.
2. Method
2.1. Visual Instruction Feedback Task
2.1.1. Task Definition
- Task = 시각적인 단서 (행동, 제스처, 이벤트 등) 만으로 사용자와 상호작용
- 정해진 시간 안에 인식하고 피드백을 제공해야
- 모든 피드백은 2인칭 관점 (너)로 이뤄지고 대화형 시나리오에 국한
| # | 서브태스크 | 설명 | 비디오 | QA | QA유형 |
| 1 | Visual Wake-Up | 사용자가 시각적 신호(예: 손 흔들기)로 대화를 시작 | 100 | 100 | Open-ended |
| 2 | Anomaly Warning (AW) | 갑작스러운 이상 행동(예: 넘어짐, 폭발)을 감지하고 즉시 경고 또는 도움 | 200 | 200 | Open-ended |
| 3 | Gesture Understanding (GU) | OK, GOOD, ONE, TWO 등의 제스처를 해석하고 적절히 반응 | 200 | 200 | Open-ended |
| 4 | Visual Reference (VR) | 사용자가 손가락으로 물체를 가리키면 그 물체가 무엇인지 파악 후 설명 | 200 | 200 | Multi-choice |
| 5 | Visual Interruption (VI) | 사용자가 중간에 "그만" 등의 제스처로 응답 중단을 요청하면 즉시 멈춤 | 100 | 100 | Open-ended |
| 6 | Humor Reaction (HR) | 시각적으로 웃긴 상황에 적절히 반응하여 정서적 교감 제공 | 100 | 100 | Open-ended |
| 7 | Visual Termination (VT) | 대화를 종료하는 제스처 인식 (문맥에 따라 wake-up과 구분됨) | 100 | 100 | Open-ended |
2.1.2. Dataset Construction
- 공개 데이터셋
- Anomaly Warning : OOPS, Holmes-VAU
- Gesture : Jester
- Humor : FunQA
- Social Cue : Social-IQ, IntentQA, SMILE
- 자체 데이터셋
- 약 1.2만개 영상
- 평가 방법
1. Time Accuracy
- 모델이 응답한 시점 T가 정답 시간 범위[t1, t2 + T]에 포함되어야함
2. Text Score
- 대답의 내용이 시각적 행동이나 이벤트를 반영해야함
- 상황에 맞고 긍정적이며, 사용자를 도와주는 피드백이어야 함
- GPT-4o가 채점 (0 - 5점)
3. Overall Score
- 각 서브태스크에 대해 O = 평균(T_acc × S)
- 정확한 타이밍 + 적절한 답변 모두가 중요
2.2. The ViSpeak Model
2.2.1. Model Architecture

기존 LLM은 Turn-taking 방식으로 말 중간에 Interrupt가 어렵습니다. 따라서 ViSpeak은 사용자 입력과 에이전트 응답을 별도의 Stream으로 분리합니다.
<Stream 구조>
Stream 1 : User Input (비디오, 오디오, 텍스트 등)
Stream 2 : Agent Input (History)
두 Stream은 LLM에 넣기 전 Weighted Sum으로 통합합니다. (선형 레이어로 학습)
<Segmentation>
LLM에 넣기 전 스트리밍 입력을 처리하기 위해 시간 단위로 분할합니다.
비디오 : 1 fps
오디오 : 1 sec
각 세그먼트는 <seg> 토큰으로 구분되고, LLM은 반드시 <seg>토큰에서만 응답을 시작할 수 있습니다.
<응답 포맷 / 모달리티 구분>
VITA 방식을 차용해 답변의 시작은 다음과 같이 다르게 표시합니다.
| 입력 유형 | 응답 시작 토큰 |
| 텍스트 | ⇐ |
| 오디오 | ⇒ |
| 비주얼 | ⇓ |
예를 들어, 사용자가 손을 흔들면, 모델은 ⇓ Nice to meet you
<언제 말할지 결정>
텍스트 응답은 기존 LLM의 Next Token Prediction으로 충분하기 때문에 다음 토큰이 예상되면 ⇐ 을 출력하고 계속 말합니다.
비주얼 응답은 단순한 토큰 예측 방식으로는 언제 말할지 판단이 불가능합니다. 따라서 별도의 binary classification head ("informative head")를 도입합니다. (MMDuet에서 착안)
- binary classification head ("informative head") 는 "지금 말해야 하나?" 여부를 판단합니다.
- 예를 들면 예측 점수가 임계값을 넘으면 말을 시작
오디오 응답의 Turn-taking 문제는 단순화 목적으로 고려하지 않았습니다.
<전체 흐름>
스트리밍 입력 → 이미지/오디오 인코딩 → 시간 단위 세분화 → <seg> 토큰 추가 → [사용자 입력 스트림 + 에이전트 응답 스트림] → 결합 → LLM 처리 → ⇐ / ⇒ / ⇓ 로 시작하는 응답 생성 + informative head가 응답 타이밍 조절
2.2.2. A Three-Stage Finetuning Recipe
스트리밍 대응 LLM을 처음부터 훈련하는 것은 너무 많은 리소스를 요구하기 때문에 기존 멀티모달 모델 (VITA 1.5)를 기반으로 파인튜닝을 했습니다.
2.2.2.1. Stage 1. Template Alignment
기존 오프라인 모델을 스트리밍 구조에 적응시키는 단계입니다.
VITA 1.5에서 270만개의 샘플을 200만개의 샘플로 압축해 빠른 학습을 했습니다.
2.2.2.2. Stage 2. Streaming Finetuning
스트리밍 기반 QA 능력과 Proactive output 능력을 향상시키는 단계입니다.
timestamp가 포함된 데이터로 실시간 반응성을 학습하고 이 단계에서 Informatve head 훈련을 진행합니다.
MMduet을 포함해 총 65.7만개의 샘플로 학습했습니다.
2.2.2.3. Stage 3. Vispeak-Insturct Finetuning
최종적으로 논문에서 직접 수집한 Visual Instruction Feedback 태스크 데이터셋으로 튜닝합니다.

ViSpeak은 오픈소스 중 최고 성능을 기록했습니다.

자체제작한 ViSpeak-Bench 입니다. 7가지의 서브태스크를 포함해 인간 평가과 비교한 결과입니다.
3. Experiment
2.1. Implementaton Detail
- 기반 모델 : VITA 1.5
- LLM : Qwen2.5 7B
- 이미지 인코더 : InternViT300M (448px)
- 오디오 인코더 : VITA 자체 (341M 파라미터)
- 프레임 샘플링 : 1fps
- H/W : L20 GPU 32장
- Informative Head 임계값 : 0.35
2.2. Ablation Study
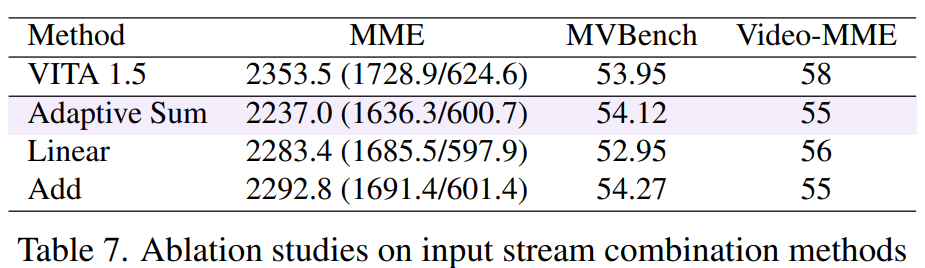
2 Stream 구조에서 Weighted Sum을 사용했을 때 (Adaptive Sum), 단순히 Feature 차원으로 ADD, 두 Stream을 붙이고 선형 통과(Linear) 방식을 비교했는데 성능 차이는 비슷했으나 이론적으로 가장 유연한 Adaptive Sum을 기본값으로 사용했습니다.

모델이 스스로 시각적 단서에 반응할 수 있는지 확인하는 실험에서 Inform Head를 사용하고 LLM과 공동으로 학습했을 때, 그리고 <seg> 보다 마지막 visual 토큰이 행동 경계 인식에 더 효과적이었습니다.

ViSpeak-Instruct 학습 시, 오프라인 데이터 포함 여부가 성능에 영향을 미치는지 분석을 했습니다. (HR(Humor Reaction), GU (Gesture Reaction)) 오프라인 데이터 포함 시, 제스처와 유머 인식 성능이 올라갔습니다.

파인튜닝이 진행될 수록 기존 성능은 유지하면서 스트리밍+시각 지시 반응 성능이 강화되는 것을 확인할 수 있었습니다.
4. Conclusion
스트리밍 영상 이해에서 사람과의 자연스러운 상호작용을 위한 새로운 태스크를 제안했고, 추가적인 데이터 구축, 3단계 파인튜닝으로 학습된 ViSpeak 모델로 GPT-4o급의 SOTA 성능을 확보했습니다.
아직 유머와 이상 상황 감지(추론 능력)는 아직 부족한 것으로 파악됩니다.