1. Introduce
아직 아카이브에 있지만 발표 준비 중인 것 같은 2024년에 공개된 Dynamic Gaussian Fusion from Casual Videos via 4D Motion Scaffolds 논문을 리뷰합니다. 가칭은 MoSca고 이번 글에서도 MoSca로 부를 예정입니다.
이번 글에서는 Gaussian Splatting 관련된 내용은 생략했습니다. 조만간 Gaussian Splatting 논문도 리뷰할 예정입니다. background가 되는 논문을 먼저 리뷰해야하는데 MoSca가 좀 더 내가 하고자하는 방향에 맞는 것 같아서 급하게 읽어봤습니다.
기존 재구성 논문들은 Multi-View를 많이 쓰고 있었습니다. 근데 Video footage에서는 Multi-view가 제한적입니다. 예를 들면 단안 카메라에서 촬영된 Video는 하나의 시점에서만 촬영하고 동일한 장면을 여러 각도에서 캡처하려면 다중 카메라 시스템이 필요하지만, 이는 일반적인 Video에서는 불가능합니다.
따라서 본 논문에서는 단안 카메라에서 촬영된 Video(single view) 영상을 4D로 재구성하는 방법을 소개합니다.
전체적인 전개는 다음과 같습니다.
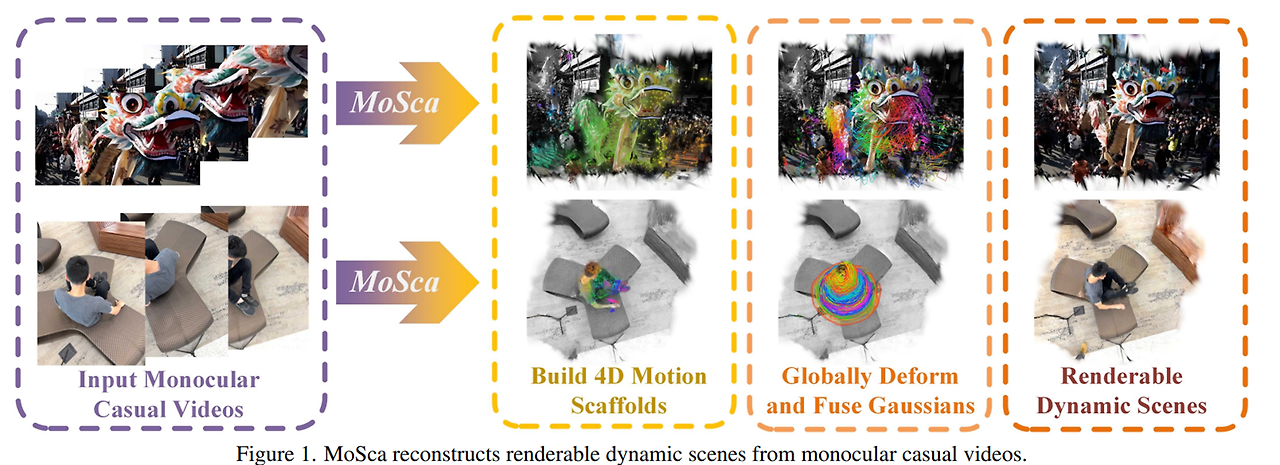
단안 영상이 들어오면 4D Motion Scaffolds 를 생성하고 움직이는 물체에 대해서 시간과 공간내에서 시각적으로 표현 후, Gaussian Splatting을 사용해 렌더링합니다.
2. Method

(A) 단안 영상이 Input으로 들어오면, Pretrained 2D Vision Model로 2D 이동궤적, depth, optical flow, epiplolar 에러 등을 추출합니다.
(B) 정적인 배경과 움직이는 물체를 분리하고 카메라 내외부파라미터를 추정하여 장면의 기초 구조를 성정합니다. Optical Flow와 Epipolar를 통해 정적배경을 동적 물체와 분리합니다.
(C) 2D 예측 데이터 (이동궤적, depth 등) 기반으로 3D Motion Scaffold(그래프)로 lifting 하여 3D노드와 엣지로 구성된 그래프 형태로 표현합니다.
손실함수는 ARAP (As-Rigid-As-Possible) + 속도 및 가속도 손실함수를 사용합니다.
- ARAP
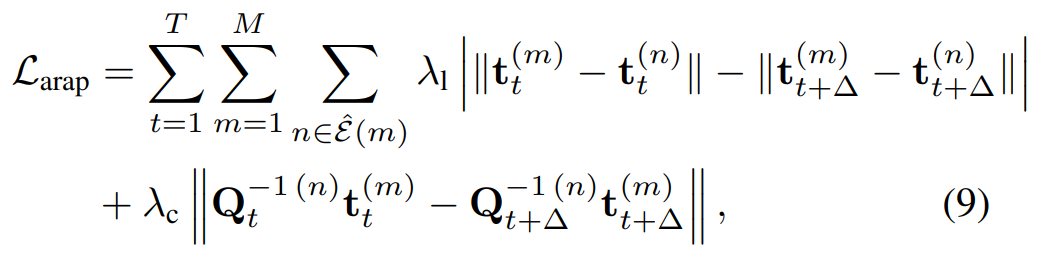
첫 번째 항 : 시간의 흐름에 따라 두 노드 간의 거리가 계속 유지되도록 합니다. 이는 변형 관정에서 노드 간의 상대적 배치를 보존해 물리적 일관성을 유지시켜줍니다.
두 번째 항 : 노드 n의 로컬 좌표계에서 노드 m의 위치가 시간에 따라 크게 변하지 않도록 보장합니다. 이는 로컬 좌표계 기준으로 변형의 매끄러움을 유지시켜줍니다. (예를 들어, 손목이 움직이더라도 손목과 팔과 어깨간의 거리는 크게 변하지 않습니다.)
따라서 ARAP에서는 변형이 가능한, rigid를 유지시키려고 노력합니다. 물리적으로 일관성은 유지하되, 부드럽게 변형될 수 있게 합니다. - 속도

시간 흐름에 따라 노드의 이동거리를 최소화 시킵니다. 불필요한 변형이거나 비현실적인 움직임을 최소화 시키려고 합니다. - 가속도

시간 흐름에 따라 노드의 가속도도 최소화시킵니다. 역시 이 부분도 움직임이 갑작스럽게 변하지 않도록 제한합니다.
전체 손실함수 (ARAP + 속도 및 가속도 손실함수)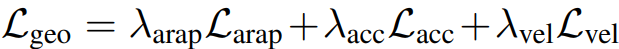
ARAP, ACC, VEL에 각각의 가중치를 두어 전체적인 손실함수를 구성합니다.
(D) Motion Scaffold의 노드 위치 기반으로 Gaussian Splatting 생성하고 Fusion을 통해 시간적으로 서로 다른 프레임에서 관측된 정보를 융합한 뒤, 렌더링합니다.
각 시간마다 3D 데이터들은 Gaussian으로 표현되고, 각 시간마다 동일한 물체는 위치, 크기, 색상이 다를 수 있으니 SE(3)공간에서 각 시간 단계 간의 변형을 표현합니다.
이에 Fusion at target time은 Gaussian Splatting을 통해 모든 시간 단계의 데이터를 통합하고, ARAP 및 Photometric Loss를 사용해 최적화합니다.
전체적인 손실함수는 다음과 같습니다.
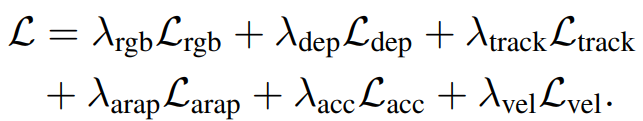
RGB Loss : 입력 프레임과 재구성된 이미지 간의 픽셀 단위 색상 차이 최소화
--> 시각적으로 사실적인 결과를 생성하기 위해
DEPTH Loss : 입력 depth와 재구성된 depth 차이 최소화
--> 거리감 및 공간적 정확성 향상
TRACKING Loss : 입력된 경로와 재구성된 물체의 경로의 차이 최소화
--> 물체의 움직임과 실제 궤적을 일치
3. Experiments
PSNR, SSIM, LPIPS를 활용해 3D 재구성 품질을 평가합니다.
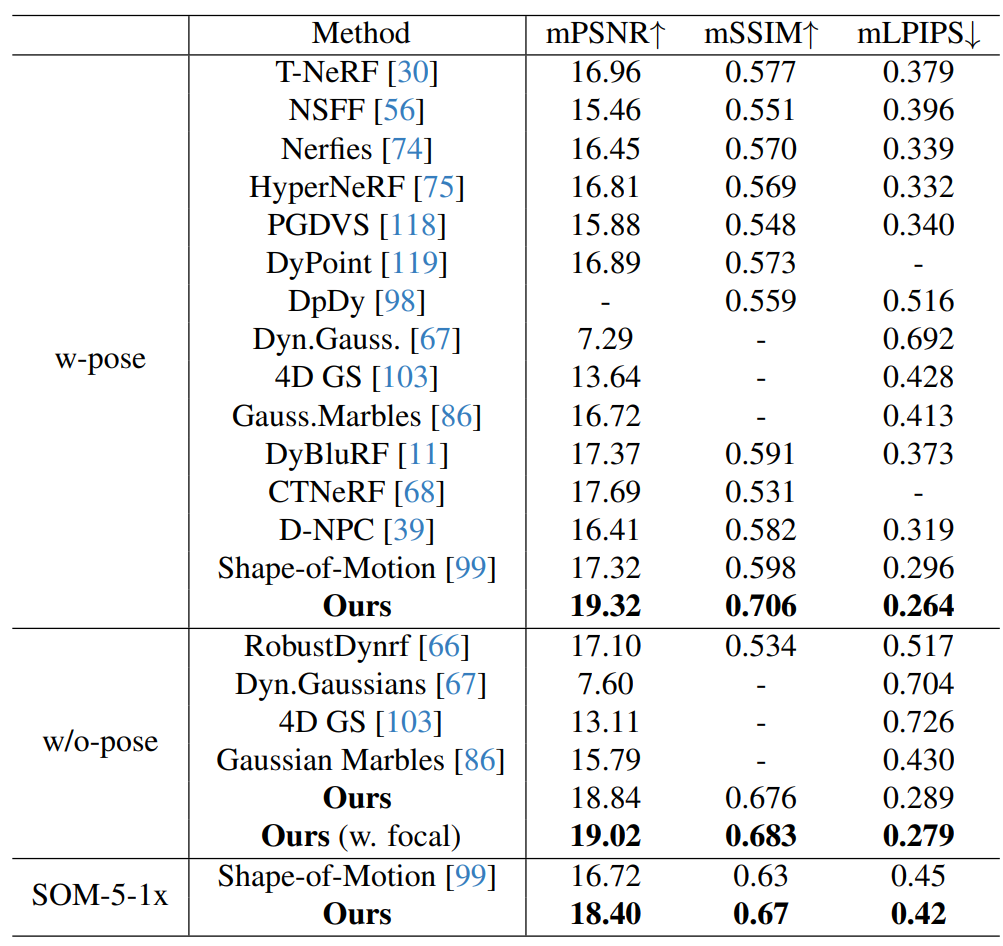
전체적으로 기존 기술 대비 높은 점수를 기록했습니다. 특히 복잡한 움직임과 역동적인 물체가 포함된 장면에서 우수한 성능을 보였습니다. 또한 렌더링 속도도 real time에 가까운 성능을 제공했습니다.

맨 위 그림 앉아있는 남자는 pose가 있을 경우입니다.

자동차 스티어링을 돌리는 장면은 pose가 없을 경우입니다.
4. Conclusion
MoSca의 한계는 다음과 같습니다.
- 매우 복잡한 움직임과 심한 occlusion은 재구성이 힘들 수 있음.
- input Video의 품질이 낮거나 움직임이 너무 제한적인 경우, 정확한 3D 구조를 추출하기 어려움.
- 매우 큰 데이터셋에서는 실시간 처리가 어려울 수 있음.
- 사람, 차량 등 특정한 동적 장면에 최적화되어 있으며, 더 다양한 장면에 일반화하기 위해서는 추가 연구가 필요함.



