이전 논문인 3D-LLM에 이어 LLM과 3D를 이어주는 초기 3D LLM 논문을 읽어보기로 했습니다.
1. Introduce
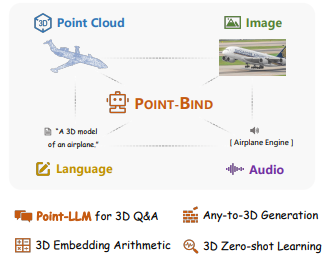
본 논문은 3D Point Cloud를 2D 이미지, 언어, 오디오, 비디오 같은 다중 모달리티와 alignment하는 3D 다중 모달리티 모델 Point-Bind와 3D 다중 모달 지시에 따른 최초의 3D LLM인 PointLLM을 소개합니다.
기존 연구의 한계점
3D Geometry 이해를 위한 연구는 2D 언어 임베딩을 이용해 3D 월드를 인식하거나, 시각적, 텍스트적의미를 결합해 3D 표현 학습을 하는 방식이 주를 이뤘습니다. 하지만 기존 연구들은 학습 단계에서 제공된 제한된 모달리티에 의해 인식 능력이 제한되는 경우가 많았습니다.
Text to 3D Synthesis는 2D 생성 모델에서 영감을 받아 텍스트 3D 생성에 대한 연구가 많이 이뤄졌습니다. 하지만 기존 연구들은 다중 모달 입력을 기반으로 한 Any to 3D 에는 한계가 있었습니다.
기존 연구들은 LLM에 내장된 사전 학습된 언어 데이터를 활용하지 못해, 3D Geometry 데이터를 효과적으로 이해하는데 한계가 있었고, 따라서 다중 모달리티와 통합된 3D 프레임워크의 개발이 필요했습니다.

따라서 첫 번째로, 본 논문에선 Point-Bind를 제안했습니다. Point-Bind는 Point Cloud를 여러 모달리티와 정렬해 통합된 3D 분석을 지원하는 다중 모달리티 프레임워크이며 주요 Contribution은 다음과 같습니다.
1. 3D와 ImageBind의 정렬
- Point-Bind는 ImageBind의 가이드를 통해 공동 임베딩 공간에서 3D Point Cloud와 다중 모달리티를 처음으로 정렬합니다. 이를 통해 3D 데이터와 다른 모달리티 간의 일관된 표현을 가능하게 합니다.
2. Any to 3D 생성
- 기존 Text to 3D를 확장해 Point-Bind는 다양한 모달리티를 기반으로 3D 생성합니다.
3. 3D 임베딩 공간 연산
- Point-Bind를 통해 추출된 3D 특징은 다른 모달리티와 결합해 그들의 Semantic을 통합할 수 있습니다. 이를 통해 교차 모달 검색을 할 수 있는데, 교차 모달 검색은 텍스트와 3D 특징을 조합해 특정 장면을 검색하거나, 이미지와 3D 데이터를 조합해 특정 콘텐츠를 찾는 기능을 할 수 있습니다.
4. 3D zero-shot
- Point-Bind는 3D 제로샷 분류에서 SOTA성능을 달성했는데, 텍스트 기반 참조 외에도 오디오 참조를 통해 3D 월드를 이해합니다. 예를 들어 오디오로 특정 장면이나 객체를 식별하거나 텍스트 명령어로 3D 환경 내 작업을 수행할 수 있습니다.

두 번째로, Point-LLM을 제안했습니다. Point-LLM은 3D LLM으로 3D Point Cloud 와 언어를 통해 3D 기반의 질의응답과 다중 모달 데이터를 처리할 수 있습니다. Point-LLM은 Point-Bind를 기반으로 LLaMA와 통합하여 개발됐습니다. 주요 Contribution은 다음과 같습니다.
1. 3D 질의응답
- Point-LLM은 3D Point Cloud 기반으로 언어 지시를 처리하여 응답하는 최초의 모델입니다. 일단 영어와 중국어가 가능합니다.
2. 효율성
- 3D 지시 데이터가 필요 없기 때문에 적은 데이터와 리소스로 학습이 가능합니다.
3. 다중 모달 및 3D 추론
- Point Cloud, 이미지, 오디오와 같은 다양한 데이터를 결합한 추론이 가능합니다.
2. Method
1. Point-Bind

1. ImageBind
먼저 ImageBind에 대해서 설명이 필요합니다. ImageBind는 다중 모달리티를 공동 임베딩 공간에 통합하는 방법을 제안한 기술입니다. 따라서 본 논문에서도 6가지의 모달리티 (이미지, 텍스트, 오디오, 깊이, 열, IMU)를 하나의 공유 표현 공간으로 정렬해 크로스 모달 zero-shot에 도움을 줄 수 있습니다. ImageBind의 특징은 다음과 같습니다.
1. Image-Pair 데이터만 사용
- 6가지 모달리티를 공동 임베딩 공간에 정렬하기 위해, 이미지와 짝지어진 데이터만 사용합니다.(모든 모달리티가 서로 직접 짝을 이루는 데이터는 필요없음)
2. 이미지의 바인딩 속성 활용
- 각 모달리티를 독립적으로 이미지와 정렬하여 모달리티 간의 간접적인 연결을 형성합니다. (텍스트 -이미지 정렬과 오디오-이미지 정렬을 통해 텍스트-오디오 간 간접적인 연관성을 형성)
3. 크로스 모달 대조 학습
- 다양한 모달리티 데이터를 대응하는 encoder에 입력해 이미지-페어 데이터에 대해 대조 학습을 수행하여 모달리티 간의 일관된 표현을 학습합니다. (텍스트 : 사과 / 이미지 : 사과사진 / 오디오 : 사과소리? -->(학습) --> 공동 임베딩 공간에 가까워짐)
* 대조 학습 (Contrastive Learning) : positive pair(dog이미지와 dog텍스트)와 negative pair(cat이미지와 dog텍스트)를 구분하고 positive pair의 거리는 줄이고, negative pair의 거리는 늘려 대상들의 차이를 더 명확하게 보여줄 수 있는 학습
이러한 ImageBind의 원리를 확장해 Point-Bind는 3D 다중 모달 프레임워크를 제안합니다.
2. Training Data
3D Point Cloud를 다른 모달리티와 정렬하기 위한 방법을 설명합니다. ImageBind의 사전 학습된 임베딩 공간을 활용해 대조학습을 통해 3D 데이터와 여러 모달리티 간의 관계를 학습합니다.
먼저 3D, 이미지, 텍스트, 오디오의 데이터 Pair를 수집하기 위해 세 가지 단계를 수행합니다.
1. 3D-이미지-텍스트 데이터 Pair
- ShapeNet(3D CAD 데이터셋) 의 각 3D PointCloud를 해당 2D 이미지와 텍스트와 연결
- 2D 이미지는 3D 모델의 Multi View로 생성
- 텍스트는 3D 모델의 카테고리 명과 64개의 사전 정의된 템플릿으로 생성
2. 3D-오디오 데이터 Pair
- ESC-50(다양한 환경 소리 데이터셋), ShapeNet
- ShapeNet의 55개 카테고리 중 실제 소리를 낼 수 있는 물체를 선택
- ESC-50에 해당 카테고리가 존재하는지 확인해서 최종적으로 9개의 카테고리 선정 후, ShapeNet의 3D 모델과 ESC-50의 오디오 클립을 연결
3. 3D-이미지-오디오-텍스트 데이터 Pair 통합
- 3D-이미지-텍스트, 3D-오디오를 매칭해 통합
- 학습 시, Point Cloud와 함께 연결된 이미지와 오디오, 텍스트 데이터를 동시에 입력해 대조 학습 --> 이를 통해 3D 데이터와 다른 모달리티 간의 정렬 관계를 학습
3. 3D와 다중 모달리티 정렬
이는 3D Point Cloud와 이미지, 텍스트, 오디오 데이터를 공동 임베딩 공간에 정렬을 하기 위한 학습 방법을 설명합니다. 이는 대조 학습을 통해 이뤄집니다.
(3D Point Cloud : P / 2D 이미지 : I / 텍스트 설명 : T_s / 오디오 : A )
3-1. 3D Point Cloud 임베딩

I2P-MAE 3D 인코더를 사용해 3D 데이터를 F_3D로 변환하는데 3D 임베딩을 ImageBind 공간에 맞추기 위해 Projection을 합니다.
3-2. 이미지 텍스트 오디오 임베딩


ImageBind 인코더를 사용해 2D 이미지, 텍스트 설명, 오디오를 각각 임베딩합니다.
3-3. 텍스트 임베딩 평균 pooling

텍스트 임베딩의 평균 pooling을 사용해 통합된 텍스트 임베딩 F_T를 생성합니다. (텍스트 임베딩의 robustness를 위해)
3-4. 대조 손실

마지막으로 대조 학습을 통해 3D Point Cloud와 다른 모달리티 간의 임베딩을 정렬합니다. (오디오가 없는 경우엔 오디오 손실을 계산에서 제외합니다.)
따라서 Point-Bind를 통해 다음과 같은 작업이 가능합니다.
Any-to-3D : 자동차 경적소리 --> 자동차 3D 생성
3D 임베딩 공간 연산 : 3D 자동차 + 바다소리 = 해변가에 있는 자동차 이미지
3D 제로샷 이해 : 시계 소리 --> 시계 3D 형태 인식
2. Point-LLM

Point-LLM은 Point-Bind를 활용하여 개발된 3D LLM입니다. 이는 LLaMA를 fine tuning 해 3D 질의응답 추론을 할 수 있습니다. 먼저 Point-LLM의 3D 기반 명령 수행 기능을 소개합니다.
1. 3D 명령 데이터 X
- 일반적으로 3D 데이터와 텍스트 명령을 연결하기 위해서는 3D 명령 데이터셋이 필요합니다. 예를 들어 3D 모델과 텍스트 명령("이 객체를 왼쪽으로 이동시켜라")의 Pair 학습이 필요한데, Point-LLM은 다음과 같은 해결방법으로 3D 명령 데이터를 사용하지 않고도 3D 기반 명령을 학습합니다.
- 공개된 이미지-텍스트 Pair만 사용해 LLaMA 를 fine tuning하고
- Point-Bind가 3D와 다른 모달리티를 같은 임베딩 공간에 정렬하기 때문에, 한 가지 모달리티(이미지(가장많음))가 LLaMA와 연결되면 다른 모달리티도 자동으로 정렬되기 때문
2. 효율적인 학습
- 일반적으로 LLM의 모든 매개변수를 조정하면 학습에 많은 시간이 소모되기 때문에 Point-LLM은 LLaMA의 대부분의 매개변수는 고정시키고, ImageBind의 이미지 인코더와 LLaMa의 언어 공간을 연결합니다. 그 이후 output으로 나온 이미지들의 특징을 LLaMA의 단어 토크에 추가하는데, 여기서 학습에 갑자기 새로운 정보가 들어오게 되면 학습이 불안정하게 될 수 있어, 넣을 때 zero로 초기화하여 점진적으로 반영시킵니다. (Zero-initialized Gating)
마지막으로 3D Point Cloud와 텍스트 질문을 처리해, 3D 데이터를 기반으로 답변을 생성하는 질의응답 과정을 설명합니다. (다중 모달리티 추론 포함)
처리 단계를 순차적으로 표현하면 다음과 같습니다.
1. 다중 모달리티 추론
2D 이미지와 오디오는 ImageBind에 의해 처리되고, 3D Point Cloud는 Point-Bind에 의해 처리됩니다. 각 모달리티는 개별적인 임베딩 벡터로 변환되는데, Addiction 연산을 통해 이미지+오디오+3D Point Cloud의 단일 통합 특징 벡터를 생성합니다.
2. Visual Cache
학습 시에는 이미지 인코더를 사용했지만, 추론 시에는 3D 인코더를 사용하기 때문에 이미지와 3D 간의 모달리티 차이가 존재합니다. 따라서 학습 데이터에서 얻은 특징을 Cache로 저장하고, 이를 Knowledge Retrieval에 사용합니다.
- 이미지 특징 --> Key-Value 구조 (Key : 이미지 특징(임베딩) / Value : 같은 이미지의 의미 정보를 포함한 특징)
- 입력된 3D 특징을 Query로 사용해 유사한 이미지 Key를 검색
- 유사한 이미지의 Value를 선택해 가중 평균을 계산
- 계산된 결과를 3D 특징에 Residual Connection으로 3D 특징 강화
3. 특징 변환 및 답변 생성
- 강화된 3D 특징을 바인드 네트워크에 입력해 LLaMA에 연결
- LLaMA가 언어 입력과 3D 데이터를 기반으로 응답을 생성
3. Experiments
실험은 다음과 같은 방식으로 진행되었습니다.
1. 3D 명령 지시 : 이 객체가 무엇인가요? 이 객체를 회전시켜라

2. 3D 교차 모달 검색 : 이 모델과 관련된 이미지를 찾아줘

3. 3D 임베딩 공간 연산 : 3D 자동차 + 바다소리 = 해변가에 있는 자동차

4. Any-to-3D : 자동차 경적소리 -> 자동차 3D 생성

5. 3D 제로샷 : 이 소리를 내는 3D 객체는 무엇인가요?

4. Conclusion
3D 데이터를 다중 모달리티와 정렬할 수 있는 프레임워크와 3D+언어를 최초로 통합한 대규모 모델에 의의가 있습니다. 현재는 3D 모델이지만 향후에는 장면 데이터도 포함하는 것이 필요해보입니다.