LLM과 3D 조합된 논문을 보다가, 제가 일전에 리뷰하던 NeRF 관련 3D 생성 분야와 LLM이 합쳐진 논문이 있어 리뷰합니다. 2024년 NeurIPS에 올라온 논문입니다.
1. Introduce
본 논문은 NeRF의 장점을 활용해 직접 처리할 수 있는 MLLM을 수행할 수 있는 새로운 기술을 소개했습니다. NeRF의 MLP 가중치를 직접 처리해 NeRF 캡션 생성, Q&A, 분류 등과 같은 작업을 수행할 수 있으며, 기존의 렌더링 없이 MLP 가중치에서 직접 정보를 추출하기 때문에 빠른 속도로 처리가 가능하다고 합니다. 캡션은 ShapeNet 데이터셋에서 훈련된 NeRF를 대상으로 자동화된 캡션 생성 프레임워크를 설계했고 추가로 텍스트 설명 데이터셋도 추가하여 더욱 정밀하게 평가가 가능합니다.
MLP 기반의 NeRF를 사용했으며, 기존 방법들은 NeRF로부터 이미지나 3D 데이터를 렌더링하고 추출하여 사용했지만, 이는 시간이 오래걸리기 때문에 LLaNA는 이러한 과정을 건너뛰고 NeRF의 MLP 가중치를 직접 입력하여 처리했습니다.
NeRF의 MLP 가중치를 임베딩 공간으로 프로젝션하고 이를 통해 NeRF의 정보를 LLaMA 2같은 Pretrained LLM이 이해할 수 있는 형태로 변환해, Pretrained LLM을 통해 캡션 생성, Q&A, 제로샷 분류를 수행할 수 있습니다.
2. Method
2.1 Neural Radiance Fields (NeRF)
MLP 기반 NeRF를 통해 출력되는 MLP 가중치(W)와 바이어스(b)를 사용합니다. 가중치에는 객체의 형상(Geometry)와 객체의 외형(Appearance) 가 포함되는데, 형상에는 3D 공간에서의 구조적 정보, 외형에는 각 좌표에서의 색상 정보가 포함됩니다.
이러한 출력값 (W와 b)을 하나의 행렬(M)로 변환시켜 다음 단계로 입력시킵니다.
2.2 Meta-encoder
메타 인코더는 nf2vec 기반을 사용하는데 NeRF의 가중치를 입력으로 받아 전역 임베딩을 생성하는 역할을 수행합니다. NeRF에서 들어온 가중치, 바이어스 행렬인 M의 각 행을 독립적으로 처리해 S개의 토큰을 생성하고, Max-Pooling하여 전역 임베딩g로 요약합니다, 이 전역 임베딩 g는 NeRF 전체 가중치에서 형상과 외형정보를 포함합니다.
전역 임베딩 g를 기반으로 Decoder가 생성한 이미지와 원래 NeRF로 부터 렌더링된 이미지간의 차이를 최소화하도록 학습합니다. 이를 통해 g가 NeRF의 중요한 정보를 효과적으로 압축하게 됩니다.
2.3 Large language and NeRF assistant
메타 인코더를 통해 출력된 전역 임베딩 g를 Pretrain된 LLaMA 2 LLM의 텍스트 임베딩 공간으로 투영 레이어 변환합니다. 투영 레이어는 NeRF 임베딩 g와 LLaMA 2의 텍스트 임베딩 공간 간의 차원을 맞추기 위해 사용합니다.
G : g의 길이(1024), T : LLaMA2의 단어 임베딩 차원
이러한 투영 레이어는 (⟨nstart⟩,ϕ(g),⟨nend⟩,w1,w2,…,wk) 형태의 Special 토큰으로 감싸져 LLaMA 2에 입력되고, 학습됩니다. Special 토큰은 NeRF 데이터를 텍스트 데이터와 명확히 구분하기 위해 사용합니다.
3. Experiment
4. Conclusion
본 연구에서 사용된 Meta Encoder인 nf2vec은 ShapeNet에서 생성된 데이터로만 사전 학습됐기 때문에, 실제 객체에 대한 일반화 성능이 떨어질 수 있습니다. 또한 MLP 기반의 NeRF를 사용했기 때문에 InstantNGP 같은 더 복잡한 아키텍쳐는 지원하지 못합니다. 추가적으로 LLaNA 는 객체 중심의 NeRF만 테스트했기 때문에 전체 장면을 표현하는 NeRF에는 적용되지 않아 추가적인 연구가 필요합니다.
최대한 빠른 시간에 많은 논문을 읽어야할 일이 생겨서, 딥하게 리뷰하지 않고, 수박 겉 핥기 수준으로 리뷰하는게 좋을 것 같아, 이제부터는 간단하게 리뷰하고 넘어가려고 합니다.
LLM과 3D 조합 시리즈를 이어갑니다. 아마 가장 최근 논문인 것 같네요. 2024년 12월에 아카이브에 올라온 논문입니다.
1. Introduce
기존 연구는 3D 데이터를 학습하기 위해 별도의 3D 장면 finetuning이 필요했고, 3D Point Cloud나 Voxel 등의 추가적인 복원 과정이 필요했습니다. 이를 통해 데이터 및 계산이 복잡했습니다. 따라서 본 논문은 RGB-D Video만을 이용해 3D 장면을 이해하고 LLM과 통합하여 MLLM으로 캡셔닝이 가능한 방법을 소개합니다.
2. Method
3.1. Frame Sampling Strategy
Input으로 들어온 RGB-D 비디오에서 3D 장면을 표현하기 위해 필요한 최소한의 비디오 프레임을 선택합니다.
프레임 선택은 Maximum Coverage Problem 방법을 사용합니다.
이 알고리즘은 주어진 비디오 프레임 집합에서 최대한 많은 복셀을 커버하는 프레임의 부분집합을 선택합니다. 가능한 모든 K 프레임 조합을 탐색하지 않고, Greedy 알고리즘을 통해 매 단계에서 가장 많은 복셀을 커버한느 프레임만 선택함으로써 더욱 효율적으로 프레임을 선택하게 됩니다.
3.2. Position-Aware Video Representation
깊이 이미지(D)와 카메라의 내(K).외적(T) 행렬을 통해 픽셀 좌표--> 글로벌 좌표로 변환합니다.
Vision Transformer (ViT)를 사용해 프레임 이미지를 패치로 분할하여 각 패치의 특징을 추출해 비디오 프레임을 비주얼 임베딩으로 변환합니다.
그 이후, 각 이미지 패치에 대응하는 3D 글로벌 좌표(패치 내에 100개 픽셀이라면 100개의 3D 좌표를 평균) Sinusoidal Position Encoding을 통해 3D 좌표로 표현합니다. 각 패치에 대해 비주얼 임베딩과 3D 좌표 임베딩을 결합합니다.
3.3. Training Objective
본 논문의 훈련 목표는 단일 모델로 다양한 3D 장면에서의 작업 (Q&A, 캡션, 앵커링)을 처리할 수 있도록 학습하는 것입니다.
3.3.1. Q&A, Dense Captioning
Cross-Entropy Loss를 통해 모델이 입력된 3D 장면에 대해 자연어로 질의응답을 수행하거나, 3D 장면의 특정 영역에 대해 캡션(설명)할 수 있도록 학습합니다.
3.3.2. 3D Visual Grounding
모델이 주어진 3D 장면에서 특정 객체를 정확히 식별하고, 해당 객체의 위치를 3D 공간에서 앵커링(지정)할 수 있도록 학습합니다.
주어진 장면에서 bounding box를 생성하고, 비주얼 임베딩+3D 좌표 임베딩을 통해 객체 표현을 생성한 뒤, InfoNCE Loss를 통해 모델이 정답 객체와 유사도를 최대화하도록 학습합니다.
3. Conclusion
본 모델은 3D 장면을 이해하는 벤치마크에서 SOTA 성능을 달성했습니다. 비디오를 통해 3D 장면을 해석하고 이해할 수 있어, 기존 모델보다 더욱 효율적인 연구입니다.
하지만 RGB가 아닌 Depth를 포함하는 비디오기 때문에 이는 확장 가능성이 있어보입니다.
이전 논문인 3D-LLM에 이어 LLM과 3D를 이어주는 초기 3D LLM 논문을 읽어보기로 했습니다.
1. Introduce
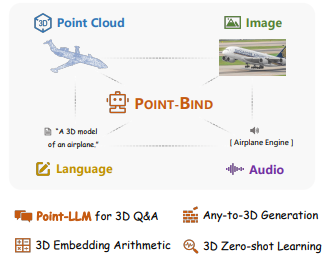
본 논문은 3D Point Cloud를 2D 이미지, 언어, 오디오, 비디오 같은 다중 모달리티와 alignment하는 3D 다중 모달리티 모델 Point-Bind와 3D 다중 모달 지시에 따른 최초의 3D LLM인 PointLLM을 소개합니다.
기존 연구의 한계점
3D Geometry 이해를 위한 연구는 2D 언어 임베딩을 이용해 3D 월드를 인식하거나, 시각적, 텍스트적의미를 결합해 3D 표현 학습을 하는 방식이 주를 이뤘습니다. 하지만 기존 연구들은 학습 단계에서 제공된 제한된 모달리티에 의해 인식 능력이 제한되는 경우가 많았습니다.
Text to 3D Synthesis는 2D 생성 모델에서 영감을 받아 텍스트 3D 생성에 대한 연구가 많이 이뤄졌습니다. 하지만 기존 연구들은 다중 모달 입력을 기반으로 한 Any to 3D 에는 한계가 있었습니다.
기존 연구들은 LLM에 내장된 사전 학습된 언어 데이터를 활용하지 못해, 3D Geometry 데이터를 효과적으로 이해하는데 한계가 있었고, 따라서 다중 모달리티와 통합된 3D 프레임워크의 개발이 필요했습니다.
따라서 첫 번째로, 본 논문에선 Point-Bind를 제안했습니다. Point-Bind는 Point Cloud를 여러 모달리티와 정렬해 통합된 3D 분석을 지원하는 다중 모달리티 프레임워크이며 주요 Contribution은 다음과 같습니다.
1. 3D와 ImageBind의 정렬
- Point-Bind는 ImageBind의 가이드를 통해 공동 임베딩 공간에서 3D Point Cloud와 다중 모달리티를 처음으로 정렬합니다. 이를 통해 3D 데이터와 다른 모달리티 간의 일관된 표현을 가능하게 합니다.
2. Any to 3D 생성
- 기존 Text to 3D를 확장해 Point-Bind는 다양한 모달리티를 기반으로 3D 생성합니다.
3. 3D 임베딩 공간 연산
- Point-Bind를 통해 추출된 3D 특징은 다른 모달리티와 결합해 그들의 Semantic을 통합할 수 있습니다. 이를 통해 교차 모달 검색을 할 수 있는데, 교차 모달 검색은 텍스트와 3D 특징을 조합해 특정 장면을 검색하거나, 이미지와 3D 데이터를 조합해 특정 콘텐츠를 찾는 기능을 할 수 있습니다.
4. 3D zero-shot
- Point-Bind는 3D 제로샷 분류에서 SOTA성능을 달성했는데, 텍스트 기반 참조 외에도 오디오 참조를 통해 3D 월드를 이해합니다. 예를 들어 오디오로 특정 장면이나 객체를 식별하거나 텍스트 명령어로 3D 환경 내 작업을 수행할 수 있습니다.
두 번째로, Point-LLM을 제안했습니다. Point-LLM은 3D LLM으로 3D Point Cloud 와 언어를 통해 3D 기반의 질의응답과 다중 모달 데이터를 처리할 수 있습니다. Point-LLM은 Point-Bind를 기반으로 LLaMA와 통합하여 개발됐습니다. 주요 Contribution은 다음과 같습니다.
1. 3D 질의응답
- Point-LLM은 3D Point Cloud 기반으로 언어 지시를 처리하여 응답하는 최초의 모델입니다. 일단 영어와 중국어가 가능합니다.
2. 효율성
- 3D 지시 데이터가 필요 없기 때문에 적은 데이터와 리소스로 학습이 가능합니다.
3. 다중 모달 및 3D 추론
- Point Cloud, 이미지, 오디오와 같은 다양한 데이터를 결합한 추론이 가능합니다.
2. Method
1. Point-Bind
1. ImageBind
먼저 ImageBind에 대해서 설명이 필요합니다. ImageBind는 다중 모달리티를 공동 임베딩 공간에 통합하는 방법을 제안한 기술입니다. 따라서 본 논문에서도 6가지의 모달리티 (이미지, 텍스트, 오디오, 깊이, 열, IMU)를 하나의 공유 표현 공간으로 정렬해 크로스 모달 zero-shot에 도움을 줄 수 있습니다. ImageBind의 특징은 다음과 같습니다.
1. Image-Pair 데이터만 사용
- 6가지 모달리티를 공동 임베딩 공간에 정렬하기 위해, 이미지와 짝지어진 데이터만 사용합니다.(모든 모달리티가 서로 직접 짝을 이루는 데이터는 필요없음)
2. 이미지의 바인딩 속성 활용
- 각 모달리티를 독립적으로 이미지와 정렬하여 모달리티 간의 간접적인 연결을 형성합니다. (텍스트 -이미지 정렬과 오디오-이미지 정렬을 통해 텍스트-오디오 간 간접적인 연관성을 형성)
3. 크로스 모달 대조 학습
- 다양한 모달리티 데이터를 대응하는 encoder에 입력해 이미지-페어 데이터에 대해 대조 학습을 수행하여 모달리티 간의 일관된 표현을 학습합니다. (텍스트 : 사과 / 이미지 : 사과사진 / 오디오 : 사과소리? -->(학습) --> 공동 임베딩 공간에 가까워짐)
* 대조 학습 (Contrastive Learning) : positive pair(dog이미지와 dog텍스트)와 negative pair(cat이미지와 dog텍스트)를 구분하고 positive pair의 거리는 줄이고, negative pair의 거리는 늘려 대상들의 차이를 더 명확하게 보여줄 수 있는 학습
이러한 ImageBind의 원리를 확장해 Point-Bind는 3D 다중 모달 프레임워크를 제안합니다.
2. Training Data
3D Point Cloud를 다른 모달리티와 정렬하기 위한 방법을 설명합니다. ImageBind의 사전 학습된 임베딩 공간을 활용해 대조학습을 통해 3D 데이터와 여러 모달리티 간의 관계를 학습합니다.
먼저 3D, 이미지, 텍스트, 오디오의 데이터 Pair를 수집하기 위해 세 가지 단계를 수행합니다.
1. 3D-이미지-텍스트 데이터 Pair
- ShapeNet(3D CAD 데이터셋) 의 각 3D PointCloud를 해당 2D 이미지와 텍스트와 연결
- 2D 이미지는 3D 모델의 Multi View로 생성
- 텍스트는 3D 모델의 카테고리 명과 64개의 사전 정의된 템플릿으로 생성
2. 3D-오디오 데이터 Pair
- ESC-50(다양한 환경 소리 데이터셋), ShapeNet
- ShapeNet의 55개 카테고리 중 실제 소리를 낼 수 있는 물체를 선택
- ESC-50에 해당 카테고리가 존재하는지 확인해서 최종적으로 9개의 카테고리 선정 후, ShapeNet의 3D 모델과 ESC-50의 오디오 클립을 연결
3. 3D-이미지-오디오-텍스트 데이터 Pair 통합
- 3D-이미지-텍스트, 3D-오디오를 매칭해 통합
- 학습 시, Point Cloud와 함께 연결된 이미지와 오디오, 텍스트 데이터를 동시에 입력해 대조 학습 --> 이를 통해 3D 데이터와 다른 모달리티 간의 정렬 관계를 학습
3. 3D와 다중 모달리티 정렬
이는 3D Point Cloud와 이미지, 텍스트, 오디오 데이터를 공동 임베딩 공간에 정렬을 하기 위한 학습 방법을 설명합니다. 이는 대조 학습을 통해 이뤄집니다.
(3D Point Cloud : P / 2D 이미지 : I / 텍스트 설명 : T_s / 오디오 : A )
3-1. 3D Point Cloud 임베딩
I2P-MAE 3D 인코더를 사용해 3D 데이터를 F_3D로 변환하는데 3D 임베딩을 ImageBind 공간에 맞추기 위해 Projection을 합니다.
3-2. 이미지 텍스트 오디오 임베딩
ImageBind 인코더를 사용해 2D 이미지, 텍스트 설명, 오디오를 각각 임베딩합니다.
3-3. 텍스트 임베딩 평균 pooling
텍스트 임베딩의 평균 pooling을 사용해 통합된 텍스트 임베딩 F_T를 생성합니다. (텍스트 임베딩의 robustness를 위해)
3-4. 대조 손실
마지막으로 대조 학습을 통해 3D Point Cloud와 다른 모달리티 간의 임베딩을 정렬합니다. (오디오가 없는 경우엔 오디오 손실을 계산에서 제외합니다.)
따라서 Point-Bind를 통해 다음과 같은 작업이 가능합니다.
Any-to-3D : 자동차 경적소리 --> 자동차 3D 생성
3D 임베딩 공간 연산 : 3D 자동차 + 바다소리 = 해변가에 있는 자동차 이미지
3D 제로샷 이해 : 시계 소리 --> 시계 3D 형태 인식
2. Point-LLM
Point-LLM은 Point-Bind를 활용하여 개발된 3D LLM입니다. 이는 LLaMA를 fine tuning 해 3D 질의응답 추론을 할 수 있습니다. 먼저 Point-LLM의 3D 기반 명령 수행 기능을 소개합니다.
1. 3D 명령 데이터 X
- 일반적으로 3D 데이터와 텍스트 명령을 연결하기 위해서는 3D 명령 데이터셋이 필요합니다. 예를 들어 3D 모델과 텍스트 명령("이 객체를 왼쪽으로 이동시켜라")의 Pair 학습이 필요한데, Point-LLM은 다음과 같은 해결방법으로 3D 명령 데이터를 사용하지 않고도 3D 기반 명령을 학습합니다.
- 공개된 이미지-텍스트 Pair만 사용해 LLaMA 를 fine tuning하고
- Point-Bind가 3D와 다른 모달리티를 같은 임베딩 공간에 정렬하기 때문에, 한 가지 모달리티(이미지(가장많음))가 LLaMA와 연결되면 다른 모달리티도 자동으로 정렬되기 때문
2. 효율적인 학습
- 일반적으로 LLM의 모든 매개변수를 조정하면 학습에 많은 시간이 소모되기 때문에 Point-LLM은 LLaMA의 대부분의 매개변수는 고정시키고, ImageBind의 이미지 인코더와 LLaMa의 언어 공간을 연결합니다. 그 이후 output으로 나온 이미지들의 특징을 LLaMA의 단어 토크에 추가하는데, 여기서 학습에 갑자기 새로운 정보가 들어오게 되면 학습이 불안정하게 될 수 있어, 넣을 때 zero로 초기화하여 점진적으로 반영시킵니다. (Zero-initialized Gating)
마지막으로 3D Point Cloud와 텍스트 질문을 처리해, 3D 데이터를 기반으로 답변을 생성하는 질의응답 과정을 설명합니다. (다중 모달리티 추론 포함)
처리 단계를 순차적으로 표현하면 다음과 같습니다.
1. 다중 모달리티 추론
2D 이미지와 오디오는 ImageBind에 의해 처리되고, 3D Point Cloud는 Point-Bind에 의해 처리됩니다. 각 모달리티는 개별적인 임베딩 벡터로 변환되는데, Addiction 연산을 통해 이미지+오디오+3D Point Cloud의 단일 통합 특징 벡터를 생성합니다.
2. Visual Cache
학습 시에는 이미지 인코더를 사용했지만, 추론 시에는 3D 인코더를 사용하기 때문에 이미지와 3D 간의 모달리티 차이가 존재합니다. 따라서 학습 데이터에서 얻은 특징을 Cache로 저장하고, 이를 Knowledge Retrieval에 사용합니다.
- 이미지 특징 --> Key-Value 구조 (Key : 이미지 특징(임베딩) / Value : 같은 이미지의 의미 정보를 포함한 특징)
- 입력된 3D 특징을 Query로 사용해 유사한 이미지 Key를 검색
- 유사한 이미지의 Value를 선택해 가중 평균을 계산
- 계산된 결과를 3D 특징에 Residual Connection으로 3D 특징 강화
3. 특징 변환 및 답변 생성
- 강화된 3D 특징을 바인드 네트워크에 입력해 LLaMA에 연결
- LLaMA가 언어 입력과 3D 데이터를 기반으로 응답을 생성
3. Experiments
실험은 다음과 같은 방식으로 진행되었습니다.
1. 3D 명령 지시 : 이 객체가 무엇인가요? 이 객체를 회전시켜라
2. 3D 교차 모달 검색 : 이 모델과 관련된 이미지를 찾아줘
3. 3D 임베딩 공간 연산 : 3D 자동차 + 바다소리 = 해변가에 있는 자동차
4. Any-to-3D : 자동차 경적소리 -> 자동차 3D 생성
5. 3D 제로샷 : 이 소리를 내는 3D 객체는 무엇인가요?
4. Conclusion
3D 데이터를 다중 모달리티와 정렬할 수 있는 프레임워크와 3D+언어를 최초로 통합한 대규모 모델에 의의가 있습니다. 현재는 3D 모델이지만 향후에는 장면 데이터도 포함하는 것이 필요해보입니다.
기존 LLMs (GPT 등)은 이미지, 동영상 등 새로운 Multi-Modal LLM을 통해 확장 중입니다. 그러나 기존 LLMs은 3D 환경을 이해하고 이를 바탕으로 추론할 수 있는 SF 영화 속 로봇에 비해서는 부족할 수 있습니다.
이를 해결하기 위해, 본 논문에서는 LLM에 3D 세계를 통합하는 (3D World를 입력으로 받고 3D 관련 작업을 수행하는 LLM) 환경을 제공합니다. 이 논문에서 소개하는 3D LLM의 중요한 이점은 다음과 같습니다.
1. 전체 장면에 대한 장기 기억 : 부분적인 관찰보다 전체적인 3D 표현 (포인트 클라우드 등)을 사용하기 때문에 장면의 모든 것을 하나의 전체적인 데이터로 저장해, 단편적인 관찰보다 훨씬 유리함.
2. 3D 속성(활용 가능성, 공간적 관계) : 3D 표현 (포인트 클라우드 등)에서 추론할 수 있기 때문에, "의자에 앉을 수 있다" 같은 활용 가능성을 전체적인 3D 데이터를 바탕으로 추론할 수 있고, "의자가 책상 옆에 있다" 같은 공간적 관계도 따로 설명하지 않아도 추론이 가능함.
본 논문에서 가장 중요하게 생각하는 첫 번째 단계는 데이터 수집입니다. 2D 기반의 이미지, 텍스트 데이터는 방대하지만, 3D 데이터는 부족하고 특히, 언어 설명과 Pair를 이루는 3D 데이터를 더욱 부족합니다. 따라서 본 논문에서는 3D 데이터와 언어 설명을 Pairing 할 수 있는 파이프라인을 제시합니다.
두 번째로는 수집된 3D 데이터를 효과적으로 활용하기 위해 3D 특징을 언어특징과 연결해야 합니다. 기존에 2D 이미지와 언어를 연결하는 방법 (CLIP 등) 을 3D에 그대로 적용하면 2D 데이터 대비 훨씬 비용이 많이 듭니다.
그래서 본 논문에서는 2D Multi-View 이미지의 사전 학습된 2D CLIP 특징을 활용해 3D 특징을 구성하는 3D 특징 추출기를 사용합니다. 다시 설명하자면, Multi-view 이미지를 입력받아 이미 VLM (BLIP-2, Flamingo) 으로 학습된 2D 특징을 그대로 사용하는데, 3D 특징은 '2D 사전 학습된 특징 공간'으로 매핑되기 때문에 기존의 2D VLM을 백본으로 사용할 수 있으며, 이를 통해 2D로 학습된 모델을 그대로 사용하면서도 3D 데이터에서 정보를 얻을 수 있는 것입니다.
그러나 2D 특징이기 때문에 3D 공간 감각을 제공하기 위해 3D Localization 메커니즘을 사용합니다.
1. 3D Position Embedding
- 추출된 3D 특징에 위치 정보를 추가합니다. (3D 포인트가 장면 어디에 있는지 숫자로 표현)
2. Location Token
- 특정 객체의 위치를 더 잘 파악하도록 학습시키기 위해, 텍스트 설명과 연결된 위치 정보 추가합니다. (의자가 방의 오른쪽 구석에 있다.)
2. Method
1. Date Generation
문제 정의 : 3D 데이터는 텍스트 설명이 부족하거나 노이즈가 많아 3D와 언어 데이터를 Pairing하기 어려움. 따라서 GPT와 같은 기술을 활용해 3D-언어 데이터를 생성하려고 시도합니다.
본 논문에서는 GPT를 활용한 세 가지 프롬프트 전략을 제안합니다.
1. Boxes-Demonstration-Instruction 기반 프롬프트
- 3D 장면의 AABB (Axis-Aligned Bounding Box) 데이터를 입력으로 사용합니다. 경계 상자는 방이나 객체의 위치나 크기 정보를 GPT에게 제공하고 텍스트로 3D 장면의 설명을 생성하도록 지시합니다. 이는 Few-shot 학습을 통해 학습시키는데, Few-Shot 학습은 GPT에 0~3개의 예시 데이터를 입력으로 제공해 모델이 어떤 유형의 데이터를 생성해야 하는지 학습시키는 방법입니다.
2. ChatCaptioner 기반 프롬프트
- ChatGPT와 BLIP-2를 결합해 3D 장면에 대한 설명을 생성합니다.
- BLIP-2 : Multi-view이미지를 기반으로 질문에 답변
- ChatGPT : 이미지를 보지 않고도 정보를 수집하기 위해 질문을 생성
BLIP-2에 Multi-view 이미지를 입력하면 ChatGPT가 장면의 다양한 영역에 대한 정보를 묻는 질문을 생성하고 BLIP-2가 대답해, 두 모델이 상호작용하여 장면 전체에 대한 종합적인 3D 설명을 생성합니다.
3. Revision 기반 프롬프트
- 하나의 3D 데이터 유형을 다른 유형으로 변환합니다.
예를 들어 "The white chair is near the table" 이라는 3D 객체의 설명이 있으면, GPT에게 "이 장면에 대해서 질문과 답변 세트를 만들고, 질문은 3D 공간 정보와 객체의 특징을 포함해줘" 라고 입력합니다.
GPT는 Q : What color is the chair near the table? A : The Chair near the table is white. 이런 식으로 출력합니다.이를 통해 3D-LLM 학습에 필요한 다양한 데이터를 생성할 수 있습니다.
2. 3D-LLM 학습
문제 정의 : 3D LLM을 처음부터 학습하기에는 어려움. 사전 학습된 2D CLIP 모델이 잇지만 3D 데이터에서는 존재하지 않음. 따라서 3D 특징 추출기와 2D VLM을 활용한 백본 설계, 3D Localizaiton 메커니즘을 제안합니다.
1. 3D Feature Extractor (3D 특징 추출기)
3D 데이터를 2D 데이터 기반으로 학습하기 위해, 3D 특징을 생성하는 세가지 방법을 사용합니다.
1. Direct Reconstruction (직접 재구성)
- RGB-D 이미지와 정확한 카메라 매트릭스를 사용해 3D Point Cloud를 생성하고, 생성된 포인트에 이미지 특징을 직접 매핑합니다.
- 언제? 정확한 카메라 Pose와 Depth가 있을 때,
2. Feature Fusion (특징 융합)
- Multi-view로 추출한 2D 특징을 gradSLAM을 통해 3D 특징 맵에 융합합니다.
- 언제? Depth에 노이즈가 있거나 카메라 Pose가 부정확할 때,
3. Neural Field
- NeRF
- 언제? RGB 데이터만 있고 Depth가 없을 경우,
2. 2D VLM 백본
3D 특징이 2D VLM과 동일한 특징 공간으로 매핑되기 때문에, 사전 학습된 2D VLM (BLIP-2, Flamingo)을 백본으로 사용합니다.
- 3D 특징 추출기를 통해 3D 데이터를 2D 특징 공간으로 변환.
- 변환된 3D 특징을 2D VLM에 입력하여 3D-LLM을 학습.
3. 3D Localizaion
3D 공간 정보를 더 잘 학습시키기 위해 사용합니다.
1. 3D Position Embedding
추출된 3D 특징에 위치 정보를 추가합니다.
- X, Y, Z 축 각각에 대해 dv/3 크기의 임베딩을 생성하고 이를 3D 특징에 결합
2. Location Token
언어 모델의 어휘에 3D 공간 정보를 나타내는 위치 토큰을 추가합니다.
- AABB를 토큰 형태로 표현 (xmin, ymin, zmin, xmax, ymax, zmax)
- 위치 토큰의 입력 및 출력 임베딩 가중치를 학습 가능하도록 설정
3. Experiments
ScanQA 데이터셋을 사용한 3D-LLM의 성능 결과를 나타냅니다. 표1은 Validation set 결과, 표2는 Test set 결과를 나타냅니다.
표 1, 2에서 나타난 결과와 같이 3D-LLM의 결과는 모두 좋았으며, BLIP2가 대부분 최고 성능을 기록했습니다.
Baseline 모델들은 명시적인 객체 표현을 사용해 제한적인 정보를 학습했기 때문에 성능이 낮게 나온 것을 확인 할 수 있습니다.
정성적인 결과로는 이러한 결과가 나왔습니다. 굉장히 잘 표현하는 것으로 보입니다.
4. Conclusion
3D 데이터를 활용하는 새로운 LLM 계열을 소개하는 논문입니다. 하지만 2D Multi view 이미지에 의존하고, 3D 데이터를 직접 학습하지 못하기 때문에 (간접적 처리) 더 효율적인 학습 방법이 요구될 수 있을 것 같습니다.